









SEO搜索引擎优化密码
 分享
分享
 评论
评论
 赞0
赞0
基础知识 一个简单例子
假如有四个文档,分别代表四部电影的名字:
The Shawshank Redemption Forrest Gump The Godfather The Dark Knight
如果我们想根据这四个文档建立信息检索,即输入查找词就可以找到包含此词的所有电影,最直观的实现方式是建立一个矩阵,每一行代表一个词,每一列代表一个文档,取值1/0代表该此是否在该文档中。如下:
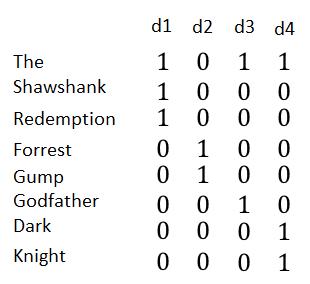
如果输入是Dark,只需要找到Dark对应的行,选出值为1对应的文档即可。当输入是多个单词的时候,例如:The Gump,我们可以分别找到The和Gump对应的行:1011和0100,如果是想做AND运算(既包括The也包括Gump的电影),1011和0100按位与操作返回0000,即没有满足查询的电影;如果是OR运算(包括The或者包括Gump的电影),1011和0100按位与操作返回1111,这四部电影都满足查询。
实际情况是我们需要检索的文档很多,一个中等规模的bbs网站发布的帖子可能也有好几百万,建立这么庞大的一个矩阵是不现实的,如果我们仔细观察这个矩阵,当数据量急剧增大的时候,这个矩阵是很稀疏的,也就是说某一个词在很多文档中不存在,对应的值为0,因此我们可以只记录每个词所在的文档id即可,如下:
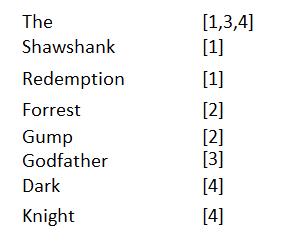
查询的第一步还是找到每个查询词对应的文档列表,之后的AND或者OR操作只需要按照对应的文档id列表做过滤即可。实际代码中一般会保证此id列表有序递增,可以极大的加快过滤操作。上图中左边的每一个词叫做词项,整张表称作倒排索引。
实际搜索过程
如果要实现一个搜索功能,一般有如下几个过程
搜集要添加索引的文本,例如想要在知乎中搜索问题,就需要搜集所有问题的文本。
文本的预处理,把上述的收集的文本处理成为一个个词项。不同语言的预处理过程差异很大,以中文为例,首先要把搜集到的文本做分词处理,变为一个个词条,分词的质量对最后的搜索效果影响很大,如果切的粒度太大,一些短词搜索正确率就会很低;如果切的粒度太小,长句匹配效果会很差。针对分词后的词条,还需要正则化:例如滤除停用词(例如:的把并且的
根据上一步的词项和文档建立倒排索引。实际使用的时候,倒排索引不仅仅只是文档的id,还会有其他的相关的信息:词项在文档中出现的次数、词项在文档中出现的位置、词项在文档中的域(以文章搜索举例,域可以代表标题、正文、作者、标签等)、文档元信息(以文章搜索举例,元信息可能是文章的编辑时间、浏览次数、评论个数等)等。因为搜索的需求各种各样,有了这些数据,实际使用的时候就可以把查询出来的结果按照需求排序。
查询,将查询的文本做分词、正则化的处理之后,在倒排索引中找到词项对应的文档列表,按照查询逻辑进行过滤操作之后可以得到一份文档列表,之后按照相关度、元数据等相关信息排序展示给用户。
相关度
文档和查询相关度是对搜索结果排序的一个重要指标,不同的相关度算法效果千差万别,针对同样一份搜索,百度和谷歌会把相同的帖子展示在不同的位置,极有可能就是因为相关度计算结果不一样而导致排序放在了不同的位置。
基础的相关度计算算法有:TF-IDF,BM25 等,其中BM25 词项权重计算公式广泛使用在多个文档集和多个搜索任务中并获得了成功。尤其是在TREC 评测会议上,BM25 的性能表现很好并被多个团队所使用。由于此算法比较复杂,我也是似懂非懂,只需要记住此算法需要词项在文档中的词频,可以用来计算查询和文档的相关度,计算出来的结果是一个浮点数,这样就可以将用户最需要知道的文档优先返回给用户。
 猜你喜欢
猜你喜欢
评论(0人参与,0条评论)
发布评论
最新评论